Since 2024, INTERACT Premium offers an offline, AI-based auto-Transcription module.
IMPORTANT: This can be a tremendous time saver, but because AI usually tries to produce a grammatical correct sentence AI-transcription does not work for all situations.
Sometimes, the utterances are no real words, the spoken dialect is unknown, or the mistakes and repetitions/stutter situation are of special interest.
In these cases, manual transcriptions are still required.
The AI-generated transcription MUST ALWAYS be verified by the user!
After correct installation, this module enables you to auto-transcribe any video with clear audio locally - fully GDPR compliant.
For AI-based transcriptions, the required GPU power on a CUDA compatible graphics board depends on the selected model.
Note: If your graphics board does not support CUDA, all calculations must be handled by the CPU, which is much slower and not recommended for any of the larger models.
Available Language Modells
Below a list that indicates the amount of FREE GPU-Memory required per Model:
oModel "tiny": 1 GB
oModel "tiny.en": 1 GB
oModel "base": 1 GB
oModel "base.en": 1 GB
oModel "small": 2 GB
oModel "small.en": 2 GB
oModel "medium": 5 GB
oModel "medium.en": 5 GB
oModel "large-v1": 10 GB
oModel "large-v2": 10 GB
oModel "large-v3": 10 GB
oModel "large": 10 GB
oModel "large-v3-turbo": 6 GB (= "turbo")
oModel "turbo": 6 GB (= "large-v3-turbo")
So if you select one of the larger models, but your computer has a lesser graphics processor than required for the selected modell, transcription will not work.
Note: Mac user with a Silicon Chip (M1, M2, M4) can use all Language Models, if enough free RAM is available.
*) The two "turbo" models are a compressed version of the "large-v3" model with about 50% of its original parameters and drastically fewer decoder layers (4 vs. 32).
IMPORTANT: You will need to test what model works best for you. Depending on slang, dialect or timbre, a different model might perform better.
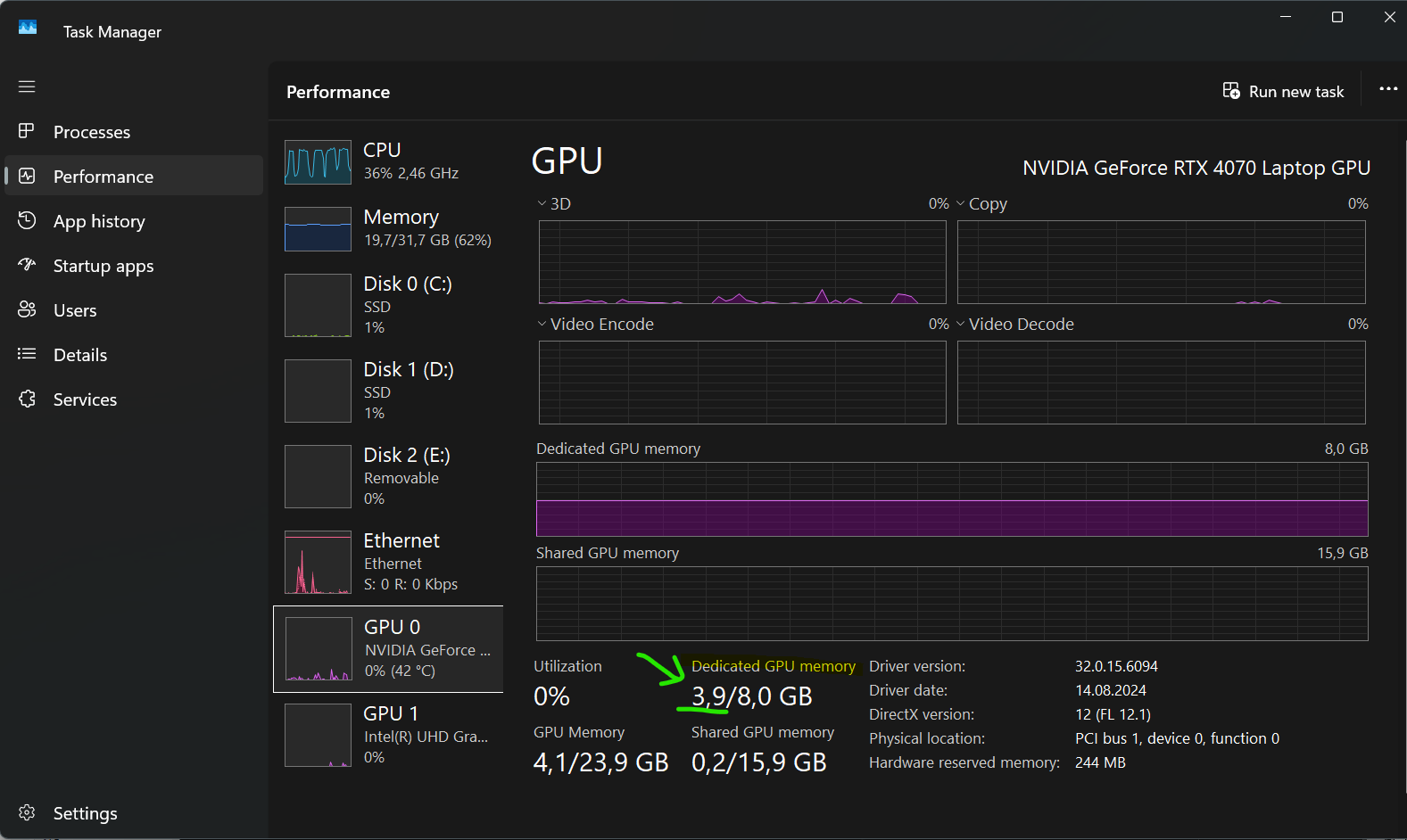
Check Free GPU-Memory
It is easy to check the situation on your computer:
•Open the Windows Taskmanager
•Switch to the Performance tab.
•Activate the Nvidia GPU section
•Check the first value under Dedicated GPU memory to verify the amount memory available for the transcription routine:
IMPORTANT: During the installation of INTERACT and when using another model for the auto-transcription, an internet connection is required to download the required packages. We NEVER upload your recordings!
Start an Automated Transcription
▪Open you video in INTERACT
▪Open an INTERACT data file.
▪Create a DataSet by clicking the Add Set ![]() button.
button.
▪Click Insert - Multimedia link - To DataSet ![]()
Or...
▪Make a right click inside the corresponding DataSet.
▪Choose Insert file reference > Link current videos to current DataSet from the context menu.
▪Make sure you can open your linked video by double-clicking a time stamp of the DataSet, otherwise the transcription tool is not able to 'find' the video.
Start Auto-Transcription
▪Open the configuration dialog with the command Text - Text analysis > Autotranscribe-Whisper.

The configuration dialog appears:


With those default settings, you already receive a rather good transcription of your video.
Speech and text options
Model - The selected model determines both the quality of the result and the time it takes to complete the transcription.
The base Model is a very good compromise.
For a rough index of the spoken words, even the tiny model might be sufficient.
You'll need to test which model works best for your videos and hardware setup.
Repetitive Transcription passes
This drop down list offers the following options:
oSkip file and do not create Events - If the video has already been transcribed, nothing happens
oOverwrite and transcribe again - Previous transcriptions are overwritten and the video is processed again.
oUse existing transcript for creating Events - Previous transcriptions are used to re-create Events in the current data file.
Add transcripts as INTERACT Events - This option ensures the automated creation of INTERACT Events. If you clear this option, you can import the SRT file into INTERACT later.
Speaker recognition options
Note: Speaker recognition only works if voices are distinct and speech sequences are long enough. Participants with similar voices will receive the same speaker ID.
You need to manually verify the results and may need to change the speaker ID for certain Events.
▪Activate the option Perform speaker recognition
Specify the number of speakers in your video, to prevent the identification of speakers that are not there.
| TIP: | If speaker detection is not required or difficult due to the similarity in voices, or your computer does not meet the requirements, clear the Perform speaker recognition option. This skips the speaker identification and all Events receive the same Speaker label. |
Exporting Options
Transcript format - Specifies the file format of the resulting text file. SRT and VTT are specific sub-title formats that can also be imported directly into INTERACT.
Transcript type - Specifies how the Events are created: Per sentence or per Word. A per Word transcription creates an Event for every word, which results in accurate timing per word.
Highlight words on subtitles - Only of interest if you are indeed planning on using the exported sub-title file for a video, like on YouTube.
Output path
Specifies where the transcript file is stored. Creating this file in the same directory as the video makes it easy to find it.
Transcription Process
The Model you select determines the quality of the transcription.
The better the quality, the longer it takes for the transcription to complete.
IMPORTANT: Larger Models require much more computer resources and will not work on every system!
Check the Requirements listed at the start of this topic.

The length of a video and the number of spoken words is another important factor for the duration of the task.
Some indications about the duration of the transcription process:
oA 30 second video running on a decent Corei7 CPU takes about 30 seconds when using the base model, but 5 Minutes when using the medium model.
oThe same 30 second video on a correctly configured GPU takes less than 20 Seconds for the Medium model and about 3 minutes for the Large model (if your GPU offers enough memory)
These are only rough estimates and cannot be multiplied linearly for longer video, but it indicates the difference between those two models.