Wenn Sie die Beobachtungen verschiedener Beobachter (rater) vergleichen möchten, bietet INTERACT Ihnen eine Inter-rater-reliabilität-Überprüfung (IRR), basierend auf 'Cohens Kappa'.
Die Kappa-Formel kann mehrere Beobachter vergleichen, wenn:
oFür jeden Beobachter die Daten in einem separaten Dokument vorliegen.
Eine Datei mit den Daten von "Beobachter A" und eine zweite Datei mit den Daten von "Beobachter B".
oDie Dokumente über die gleiche Struktur verfügen, d.h sie gleiche die Anzahl an Gruppen und Sets aufweisen und natürlich die gleiche Klassen!
K = (Pobs – Pexp) / (1 – Pexp) |
Hinweis: Es ist ein oft vorkommendes Missverständnis, dass 'KAPPA' einfach einzelne Codes zwischen zwei Beobachtern vergleicht. Dies ist nicht der Fall!
'KAPPA' ist eher ein Anzeichen für die Qualität Ihrer Daten und es werden viele Daten (Codes und Ereignisse) benötigt, um eine zuverlässige Wahrscheinlichkeitsberechnung durchzuführen.
'KAPPA' ist dabei nicht dafür ausgelegt, für nur einen Code in einer Klasse berechnet zu werden.
Die in INTERACT enthaltene 'KAPPA'-Implementierung bietet zusätzlich einen prozentualen Überblick pro Dokument, basierend auf den gefundenen Paaren, sowie eine grafische Visualisierung aller Paare (korrekte und falsche), um ein besseres Verständnis der Daten zu erhalten.
Der Kappa-Wert kann über Änderungen der Standard-Parameter optimal auf Ihre Daten eingestellt und geändert werden.
Hinweis: Es gibt keinen Gesamt-Kappa für mehrere Klassen. Mr. Cohen entwickelte die Kappa-Formel für fortlaufende, vollständige Kodierungen. INTERACT-Daten sind üblicherweise weder fortlaufend noch vollständig, wenn sie über mehrere Klassen verteilt sind.
Kappa calculation largely depends on probability calculation.
This means that the resulting value is more realistic for larger data pools.
WICHTIG: Um die Relevanz des resultierenden KAPPA-Wertes zu verbessern, führen Sie am besten mehrere Beobachtungen aus derselben Studie zusammen.
So erstellen Sie separate Kompilationsdateien pro Beobachter: Führen Sie die relevanten Dateien für "Beobachter A" in einer Kompilationsdatei zusammen und führen Sie die Beobachtungen von "Beobachter B" in einer zweiten Kompilationsdatei zusammen.
Dateien von verschiedenen Kodierern sollten NICHT zusammengeführt!
Stellen Sie sicher, dass die Reihenfolge der Sets (=Session) in beiden Dateien gleich ist und die Schreibweise der Codes identisch ist. Die KAPPA-Routine vergleicht zunächst Set für Set und akkumuliert anschließend die gefundenen Paare und Fehler für die Kappa-Berechnung.
Kappa durchführen
Um Dokumente von unterschiedliche Beobachter, die dieselben Klassen und Codes enthalten, miteinander zu vergleichen, gehen Sie bitte wie folgt vor:
▪Alle geöffneten Dokumente schließen.
▪Dann in der Werkzeugleiste auf Auswerten - Zuverlässigkeit - Kappa klicken.
Der folgende Dialog erscheint, in dem Sie die Vergleichsebene auswählen können:
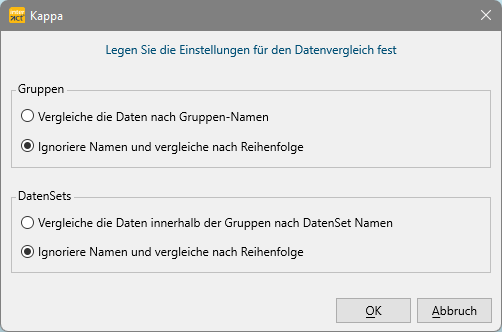
Diese Auswahl ist sehr wichtig, da der Vergleich pro DataSet erfolgt:
![]() Der Reihe nach - Wenn die Reihenfolge aller DatenGruppen und DatenSets in den einzelnen Dokumenten identisch ist, können Sie die Namen ignorieren. Verwenden Sie in diesem Fall die zweite Option!
Der Reihe nach - Wenn die Reihenfolge aller DatenGruppen und DatenSets in den einzelnen Dokumenten identisch ist, können Sie die Namen ignorieren. Verwenden Sie in diesem Fall die zweite Option!
| Nach Name - Wenn die Reihenfolge der DatenSets nicht identisch ist, muss für die DatenGruppen und DatenSets der exakt gleiche Name für die entsprechenden Sets und Gruppen in beiden Dokumenten in das Beschreibungsfeld eingegeben werden. |
▪Wählen Sie die zutreffende Struktur und bestätigen Sie den nächsten Dialog mit OK.
Als nächstes erscheint der Kappa Parameter Dialog.
| TIPP: | Um die Relevanz des KAPPA-Ergebnisses zu verbessern, können Sie pro Beobachter eine separate Kompilationsdatei erstellen: Führen Sie die relevanten Dateien für 'Beobachter A' in einer Kompilationsdatei zusammen und machen Sie das gleiche für die Beobachtungen von 'Beobachter B' in einer zweiten Kompilationsdatei. KAPPA basiert weitgehend auf der Wahrscheinlichkeit, weshalb größere Datenpools zu einem besseren/realistischeren KAPPA-Wert führen. |
WICHTIG: Für die Berechnung von Kappa dürfen KEINE Dateien von verschiedenen Codern zusammengeführt werden!